Juho Ylä-Jääski

Links
Using a Policy Gradient Algorithm to Play Pong
Project description: In this project, we were given a virtual Pong environment where agents can play against each other. In this environment, two paddles represent the players and there is a ball that the players try to hit. The figure below illustrates the environment.
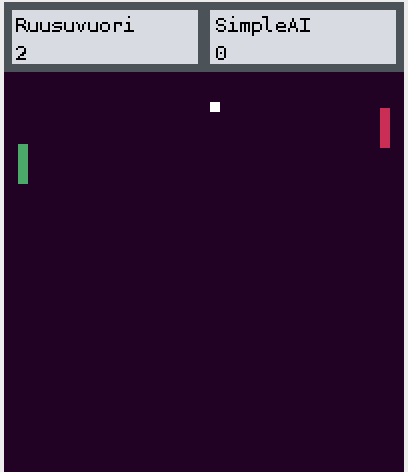
Our goal was to create a reinforcement learning agent that learns to play Pong by only observing the pixel values in the game view. We decided to implement a policy gradient algorithm with a state value baseline - this algorithm is widely known as REINFORCE. We also used PyTorch to implement a neural network that computes the policies and state values for the encountered states.
Results: As a result of training, our policy gradient agent learned to play against a simple agent opponent that was provided by the course staff. After an initial period of mindless exploration, it learned to survive in the game and its win rate began to improve. The agent’s average win rate increased through the whole training period and it reached about 85% in the training phase. All in all, the eventual win rate of our agent demonstrated that our method was successful. However, more advanced RL algorithms, such as PPO or TRPO, could be applied to this specific problem to investigate whether even higher win rates are achievable.